
DeepInfra is now live as an Inference Provider on the Hugging Face Hub. If you’ve been looking for a cheap, serverless way to run open-weight models without managing infrastructure, this is worth a look.
DeepInfra’s pitch is straightforward: pay per token, no servers to spin up, and they claim some of the lowest pricing in the industry. They’ve got over 100 models in their catalog, covering everything from LLMs to text-to-image, text-to-video, and embeddings. For the initial integration on Hugging Face, they’re focusing on conversational and text-generation tasks – think DeepSeek V4, Kimi-K2.6, GLM-5.1, and others. Support for image, video, and embedding tasks is coming soon.
How It Actually Works
The setup is pretty clean. You can use DeepInfra in two ways:
- Bring your own DeepInfra API key – Requests go directly to DeepInfra, you’re billed on your DeepInfra account. No middleman.
- Route through Hugging Face – You just use your HF token. Hugging Face passes the request to DeepInfra and bills you at the standard provider rates. No markup, which is nice. (They mention revenue-sharing might come later, but for now it’s just pass-through.)
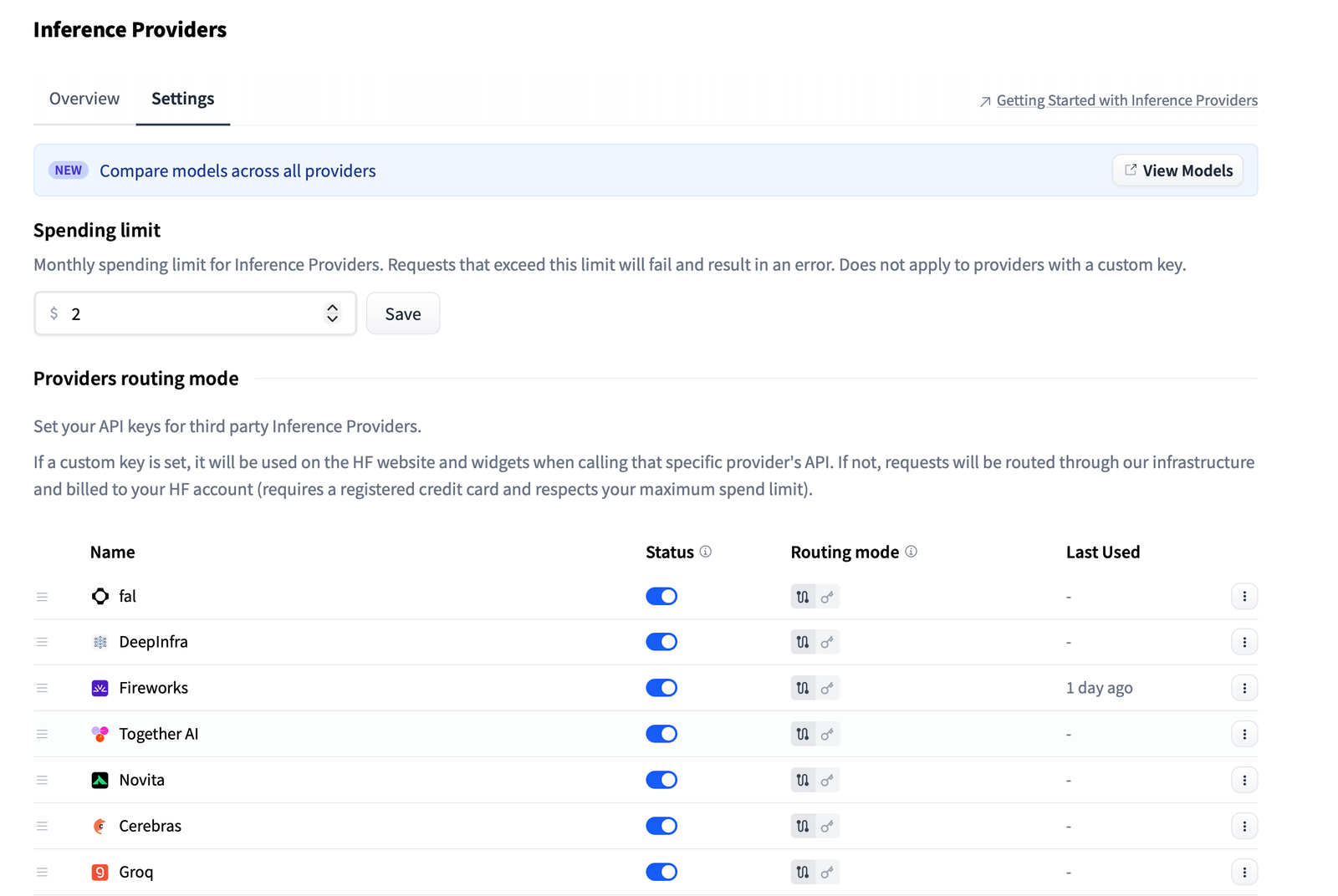
You can set your preferred provider order in your account settings, and model pages will show the compatible providers sorted by your preference. Good UX touch.
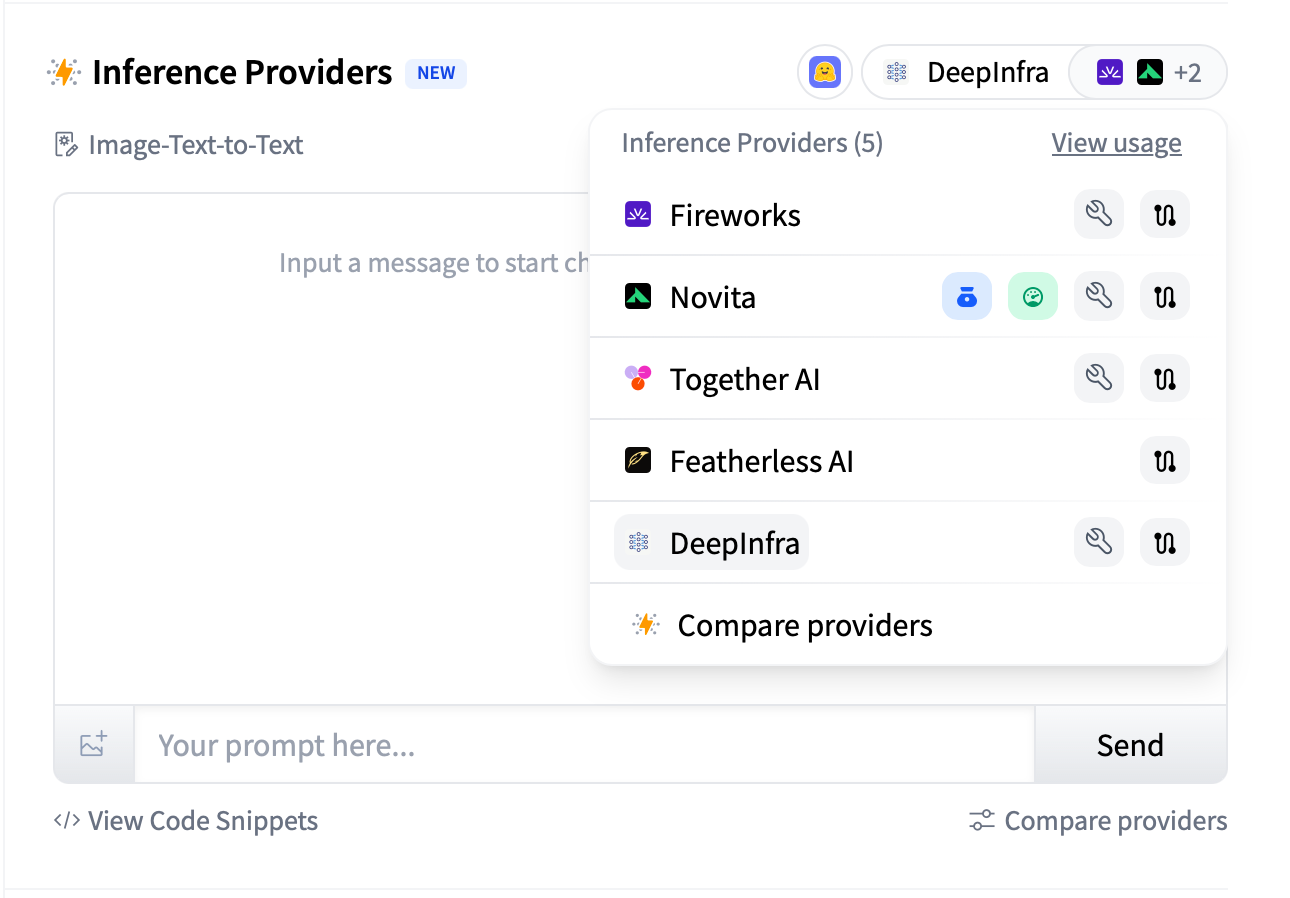
From Code
If you’re using the Hugging Face SDKs (Python huggingface_hub >= 1.11.2 or the JS @huggingface/inference), DeepInfra is available out of the box. You can also call it via the OpenAI-compatible endpoint, which is handy if you’re already using that SDK:
import os
from openai import OpenAI
client = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key=os.environ["HF_TOKEN"],
)
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro:deepinfra",
messages=[
{"role": "user", "content": "Write a Python function that returns the nth Fibonacci number using memoization."}
],
)
print(completion.choices[0].message)
The :deepinfra suffix tells the router to send the request to DeepInfra. Simple.
Agent Frameworks and Billing
This isn’t just for direct API calls. The Hugging Face Inference Providers are integrated into agent frameworks like Pi, OpenCode, Hermes Agents, and OpenClaw. So you can plug DeepInfra-hosted models into those tools without extra configuration. That’s genuinely useful if you’re building agentic workflows.
On billing: PRO users get $2 worth of inference credits every month, usable across providers. That’s a nice perk if you’re already on the PRO plan. Free users get a small quota too, but honestly, if you’re doing anything serious, spring for PRO.
My Take
DeepInfra joining the provider ecosystem is a good move. The serverless model makes sense for a lot of use cases – you don’t want to manage GPU instances just to run a chatbot. The pricing is competitive, and the model selection is solid, especially if you’re into the latest open-weight LLMs.
One thing I’d like to see: more clarity on which models are available through DeepInfra vs. other providers. The documentation page lists them, but it’d be nice to have that info directly on the model cards. Also, the “coming soon” for other task types feels a bit vague – I hope they roll out text-to-image and embeddings support quickly, because that’s where a lot of practical use cases live.
Overall, if you’re already on Hugging Face and want a no-fuss way to run inference, give DeepInfra a shot. The routed billing model means you don’t need another API key, and the SDK integration is seamless. Just be aware that you’re trusting Hugging Face’s router – but for most people, that’s fine.
If you have feedback, the team is collecting it here: https://huggingface.co/spaces/huggingface/HuggingDiscussions/discussions/49
Comments (0)
Login Log in to comment.
Be the first to comment!